
はじめに
囲碁の世界的な棋士が、英DeepMind社が開発した囲碁用人工知能「AlphaGo(アルファ碁)」に破れたことが大々的に報じられたのは2017年の3月だった。日本の専門家の間では、人工知能がトップの囲碁棋士を破るには10年を要する、との見方が一般的だったが、これが簡単に覆された。
2016年12月には、「現在ある職業のおよそ半数は、将来人工知能等で置き換えられる」 1) などとの予想も発表されていた。当時、この予想に疑念を抱いて聞いた人々も、囲碁において、人工知能が人間より強いらしいと聞いて、昨年12月の発表を現実的なものと受け止め始めたかもしれない。
最近の人工知能の報道において、必ずといっていいほど聞かれるのが「深層学習(ディープラーニング)」との語である。前出のDeepMind社もこの技術を用いており、名称の「Deep」がそれを象徴している。
これまでの、人工知能も「学習」を行ったとすれば、「深層」は何なのか。そもそも、この世界でいう学習とは何か。そして、ディープラーニングがいかなる分野に適用できるのか。
本稿を、このようなディープラーニングにまつわる基礎的な疑問の解明の一助となることを期待したい。
ディープラーニングの威力
ディープラーニングは、2000年代半ばより現れ、瞬く間に人工知能研究の世界を席捲した。その有効性を明確に示したのは、音声認識の認識率である。
研究者たちが用いる同一の音声サンプルによる実験で、最先端の認識ソフトの誤り率は2000年代を通じて12%程度とほぼ変わらなかった。しかし、2010年以降大幅に性能を高め、現在では4%程度となっている。
この急激な性能向上の裏にはディープラーニングがある。話題となった囲碁トップ棋士との対決では、「どこに石を打つべきか」を決めるために、深層学習を行ったニューラルネットワークを作成した。
石を打つ場所を決めた後は、高速かつ効果的方法で解を探索する。石を打つ場所を決めるニューラルネットは、AlphaGo同士が対決することで強めていった 2) 。
DeepMind社は、以前にはテレビゲームを同社の人工知能(DQN:Deep Q-Network)に教えることにより、一部のゲームで人間よりも高得点をたたき出したことを発表している。
こちらは、動画を見て理解するタイプの能力も要求されており、囲碁とは違った種類の能力があったことがわかる。当時の報道では「研究チームが知らなかったゲームの抜け穴も見つけ出した」 3) とあり、DQNに深い洞察力があったことも伺える。
画像認識でもディープラーニングは用いられ始めた。2015年のCESにて米NVIDIA社は、一般公道で車輌を見分ける能力のある画像認識を公開した(図1)。

図1 NVIDIAの車輌を見分ける画像認識
NVIDIAは深層学習を用いて車種識別が可能なことを示した(CES2015)。
乗用車(セダン)、SUV、ミニバンなどを見分けるものであった。これだけでも、高度な識別であるが、「パトカー」を見分けることで来場者を驚かせていた 4) 。NVIDIAの担当者は「ディープラーニングを使い、パトカーの特徴を学習させた」と語っている。
一般車両とパトカーの間の僅かな違いも検出できる。これがディープラーニングの威力である。 通常のプログラミングでは、入力(たとえば画像)があるモデルに合致するかを比較して、結果を出す。
モデルには、「パトカーとは、屋根に警光灯(パトランプ)を載せ、アンテナが林立し...」といったパトカーの特徴が記述される。入力画像から、屋根部分を切り出して、そこに警光灯があるかないかを判断したり、アンテナの立ち方を調べて、最終的に「確からしさ」を出したりしてくることになる。
モデルを作る作業は手作業であり、画像や音声・音響といった対象分野に合わせて対象を理解した技術者が構築する。しかし、人工知能を応用すると、自動的に機械に対して学習をさせられる。
認識プログラムに画像を入力し、それがパトカーであるか否かを人が教える、という作業を繰り返せば自動的に認識プログラムができあがる。従来一般的だった方法では、屋根部分やアンテナの切り出しといった特徴抽出部分は人手で設定する必要があった。
人間は、画を見ながら、異なる事例ごとに「Yes(パトカーである)」「No(一般車である)」の入力を繰り返し、認識プログラム教育データを作る。「機械学習」と呼ばれる処理の基本で、サンプルを増やしていくと賢くなっていく。
ディープラーニングでは、先の特徴抽出部分も人手による作業が不要となる。極端な表現をすれば「何度も画を見せて、Yes・Noを与えているうちに、どこを見たらよいのか(特徴は何か)も学習し、認識能力が上がる」ということである。
そして、ディープラーニングは、それまでの手法で作られた認識器よりも高い能力を示す。これは、利用者には大変にありがたい。
パターン認識とニューラルネット
実は、人工知能にもいろいろな分野がある。手書き文字や音声認識に使われるものもあれば、推論に使われるものもある。現在話題のディープラーニングは、認識に用いられ効果を上げている。
また、ディープラーニングといっても非常に幅が広く種々の実現法がある。本稿では、「ディープ・ニューラルネットワーク(DNN)」を対象に解説する。
そのためには、重要な構成要素であるニューラルネットワーク(以下、ニューラルネット)から解説する。 ニューラルネットは神経網を模した構造で、その起源は1943年にさかのぼる。McCullochとPittsが単一の神経細胞の動作をモデル化したところから始まった(図2)。
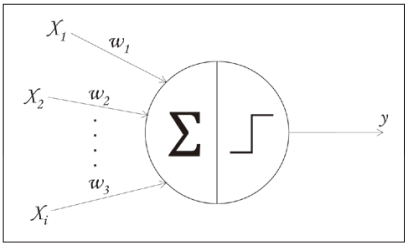
図2 McCulloch‒Pittsの神経細胞モデル
1957年にRosenblattがパーセプトロン 5) を発表し、これが識別に有効であるとわかった(図3)。ニューラルネットの多くは、パーセプトロンに起源を見ることができる。
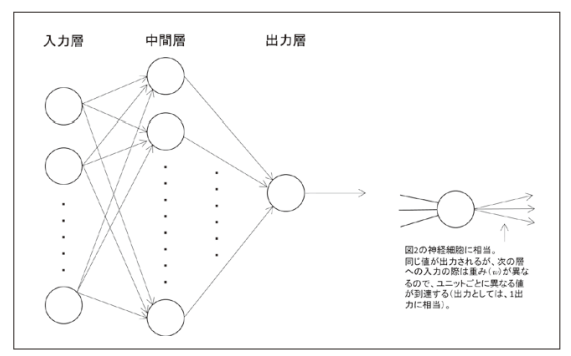
図3 最もシンプルなパーセプトロンの例
Rosenblattが最初に提案したパーセプトロン(「単純パーセプトロン」 6) と呼ぶ場合もある)をもとに、いろいろな接続形態をもつニューラルネットが登場したが、基本はこの形である。
図3のパーセプトロンは、図2の神経細胞モデルを複数組み合わせたもので、○で示した部分を「ユニット」と呼ぶ。
ユニットには、1以上の入力と1以上の出力がある。出力は同じ値が送り出される(1つの出力が複数にコピーされると考えてもよい)。このユニットが縦に並んだ一群を「層」と呼び、図3では左から入力層、中間層、出力層、となる。
人工知能分野でいう識別とは、入力パターンに対して、ラベル付け(区分け)を行うことを指している。パターンとは、「一定の規則で並んだ情報」のことである(図4)。
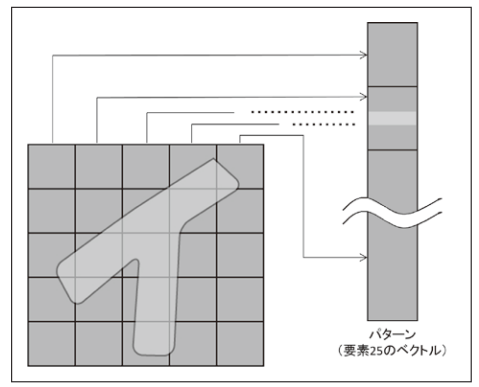
図4 パターンとは一定の規則で並んだ情報を意味する
この例の場合、各画素の値を要素とするベクトルが「パターン」
である。「イ」の字であることを識別する「識別器」は、入力
パターンから判断する。
パターンという語と画像とはまったく関係がないことに注意されたい。「パターン認識」という語が「画像認識」と同じと誤解されることがあるが、両者はまったく異なる。
入力の特徴を並べたパターン(図4の例では、要素が25あり、各要素は1bit)を区分けする作業をパターン識別と呼ぶ(図5)。
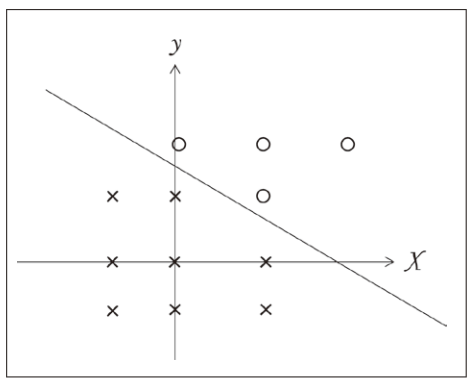
図5 入力ベクトルと結果(○と×)
入力ベクトルと結果(○と×)をプロットした両者を区切ること
で識別が可能となる。
専門的には、識別は識別器での作業を指し、認識は特徴抽出などの前処理を含めた系全体を指すが、本稿の範囲では等価と考えてよい。それゆえ、パターン識別(認識)は、音声認識にも、数列の認識にも使えるものであり、画像認識のみを指しているものではない。
識別をいかに行うか、ここで学習が登場する。図5のように、○と×という2つの結果があったとする。入力は、x軸と y 軸の値とする。このとき、○と×をより分ける線を引いて識別する。
線は、直線とは限らない。2次曲線、3次曲線となる場合もある。この区分けの線引きを自動で行うのが学習である。ここで重要なのは、「どこに線を引いたらいい」というアルゴリズムは与えられていないことである。入力値から探していく。
そして、機械学習とは、アルゴリズムが与えられていない処理対象に対して、装置(ここではパーセプトロン)が処理実現のためのモデルを自動的に作り上げていくことを指す。
ディープラーニング
ディープラーニングは、特徴抽出前の信号を処理する多階層ニューラルネットワーク(DNN)、と定義しよう。多階層とは、3層以上を指す。1980 年代から90 年代にかけての第2 次ニューラルネットブームの際も深層化はよく議論された。
しかし、当時はDNNで学習を行う方法が見つかっていなかった。学習時には、出力層から入力層に向かって情報を伝播させながら各ユニットのパラメータの修正を行うのだが、当時の方法では、入力に近い層に修正が及ばないことが大きな問題であった。
ところが、全階層に学習を行き渡らせる方法が見つかり、多階層化が現実的になった。1998年には、画像認識に向いた畳み込みニューラルネット(Convolutional Neural Net:CNN)が考案された。
このアイデアの前に、福島が1979年に視覚神経処理をモデル化したネオコグニトロン 7) を提唱していたが、同様な考えがCNNに見られる。
ディープラーニングでは、特徴抽出部分は自動的に学習(教師なし学習)して構築される。一方、ニューラルネット全体としては、特徴抽出部分が出来上がった上で学習データを取り込んで教師あり学習(正答が与えられる学習)を行う。
現在、画像認識用のCNNは、10層以上の多層化を行うことも珍しくない。多層化が可能になったとは、アルゴリズムの進化 8) とハードウェアの進化の双方である。
特に、並列演算処理をハードウェア化した GPU は、CNN に限らず大規模なニューラルネットワークの構築に寄与している。また、インターネットを通じて画像サンプルを容易に入手できるようになったことも、研究の推進に寄与している。
ディープラーニングは、利用段階よりもはるかに大きな手間が学習段階で必要となる。演算負荷も学習段階に集中する。利用段階での処理をハード化する動きもあり、現在よりも簡単に利用できると期待されている。
一旦、ディープラーニングが完了したあとも、新しいデータにより教師あり学習を続けて精度を高めていくことは可能である。
しかし、製品を売り出す立場では、顧客が収集した学習データの正当性は検証できないため、それを使って学習させると装置の性能に悪影響を及ぼす可能性があり、製品安全性の面からも容認できない。
メーカとしては、出荷後に客先で得たデータにより不測の事態が起きないような対策を予め講じておくことが、技術者倫理の観点からも求められる。
一方、性能向上のためには、出荷後の装置によりデータを収集し、正当性、安全性を検証した上で再度の学習を行い、ソフトウェアアップデートとして新版を配布することになるだろう。
能力向上はメーカの責任で行い、使用者には開放しないといった対応が必要な場面が多いと見られる。
おわりに
ディープラーニングの基となるニューラルネットは、入力に対する反応を起こすものである。記憶を探りながら、思索を行うといったタイプの「知能」ではない。DeepMind社は「AlphaGoは、碁のルールを知らない」としているが、これはディープラーニングの特徴を見事に表している。
「周りがこのような時、ここに石を置かれることがない」ことを経験(学習)により知っているのである。囲碁のルールに当てはめて理解しているのではない。このようなディープラーニングの制約を理解しておく必要がある。
ディープラーニングは、音声・音響、画像のみならず、多くの分野で利用が始まっている。また能力の高いネットワークの組み方も各所で研究されている。
今後も、基礎研究、応用研究ともに大いに伸びるだろう。利用時のCPU負荷も、FPGA化や専用回路化でかなり負担が軽減されるはずである。ニューラルネットは、3度目のブームにして、実用化の花が咲いた。
※映像情報インダストリアル「画像認識の極み“ディープラーニング”」より転載

■参考文献
1) 野村総合研究所: 日本の労働人口の49%が人工知能やロボット等で代替可能に. http://www.nri.com/jp/news/2015/151202_1.aspx, 2015
2) Silver D et al: Mastering the game of Go with deep neural networks and tree search. Nature 529 (7587): 484-489, 2016
3) Clark L: ゲーム攻略で人間を超えた人工知能、その名は「DQN」. Wired日本版, http://wired.jp/ 2015/02/28/google-deepmind-atari/, 2015
4) 杉沼浩司: 密接に関連する車とICT. 映像新聞, 2015
5) Rosenblatt F: The perceptron: a probabilistic model for information storage and organization in the brain. Psychol Rev 65(6): 386-408, 1958
6) 馬場則夫ほか: ニューラルネットの基礎と応用. 共立出版, 東京, 1994
7) 福島邦彦: 位置ずれに影響されないパタ-ン認識機構の神経回路モデル―ネオコグニトロン―. 電子通信学会論文誌 62-A(10), 658-665, 1979
8) 久保陽太郎: ディープラーニングによるパターン認識. 情報処理 54(5): 500-508, 2013
■著者:日本大学 生産工学部/杉沼浩司、古市昌一



















コメントを残す