

人工知能の実装手法の1つとして深層学習(Deep Learning)が注目され始めたのは、2012年である。それ以降、様々な分野で深層学習を活用した検証が行われてきた。
最近では取り組みフェーズが、これまでの実験的な取り組みから、実用化を目指したものへと移行しつつある。
ところが実用化にあたっては様々な課題が顕在化しており、その壁を乗り越えられない企業も多い。本稿では、そのような課題の解決方法を紹介したい。
市場動向(実用化に向けた課題の顕在化)
すでに人工知能の応用に取り組まれている企業の方に現状を伺うと、POC(概念実証:Proof of Concept)を経て、実フィールドでの実証実験や商用化へと取り組みフェーズが移りつつあるプロジェクトが増えている。
すなわち、POCを通して、深層学習のような新しい技術が自社製品の付加価値向上や、業務プロセスの課題解決に適用する際に有効であることを確認できており、次のステップとして実際の製品や業務プロセスへの組込みに取り組み始めている。
ところが、そのようなプロジェクトでは表1のような問題が顕在化していることも多い。昨今では、深層学習をPOCレベルで実施することは容易に実施可能になってきたものの、実用化レベルまで引き上げようとすると、技術的に容易ではなく、プロジェクトによっては壁にぶつかっている(図1)
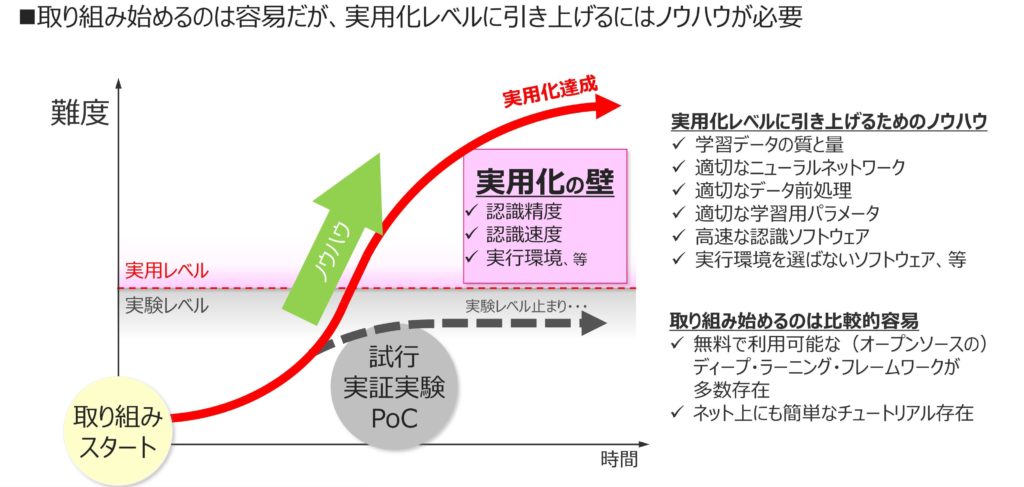
図1 深層学習プロジェクトの実用化の壁
深層学習の実用化に向けたモルフォのソリューション
モルフォでは、表1のような課題に対し、技術的なコンサルテーションや、ソフトウェアの提供を行って、お客様が深層学習の実用化するのを支援している。

表1 実用化に向けた3つの壁
1)推論精度の向上
推論精度の向上には、様々な手法があり、たとえば以下の(A)~(C)を組み合わせるとよい。モルフォは画像を対象とした推論(画像認識)を得意としているが、お客様から画像を共有いただいた上で、推論精度向上のための技術的コンサルテーションを行っている。
(A)ニューラル・ネットワーク・モデルの適切な選択とカスタマイズ
深層学習の学習や推論に用いるニューラル・ネットワーク・モデルには、各所から様々なものが提案されており、たとえばVGGNetやResNet、MobileNet等が知られている。
これらのニューラル・ネットワーク・モデルは、それぞれに特徴があり、対象とする課題によって適切に選択したり、ネットワークを構成するレイヤの構造をカスタマイズしたりすることで、認識精度を向上させることが可能である。
(B)学習用データ(教師データ)の見直し
優れた教師から学んだ生徒が賢くなるのと同様に、人工知能もまた、学習に用いる教師データの質や量によって、推論精度(賢さ)を向上させることが可能である。
学習試行後に、推論に失敗した結果の分析や選択したニューラル・ネットワークの構造を踏まえて、学習用データの量や質を適切に見直すことが重要である。
(C)学習用データに対する適切な学習前処理
学習用データに対して、適切な前処理を行うことも推論精度を向上するのに有効である。たとえば、画像認識においては、人工知能が画像の特徴を適切に学び取れるように、特徴の強調や注視領域の限定を行うこと等が有効である。
2)対象デバイスでの推論速度の向上
一般に、深層学習における推論精度を向上しようとすると、ニューラル・ネットワーク・モデルのサイズは大きくなる傾向にある。それは、ニューラル・ネットワーク・モデルを大きくすることにより、重みなどのパラメータの数が増え、学習対象の特徴をより細かに(表現力高く)学び取れる可能性が増すからである。
ところがニューラル・ネットワーク・モデルのサイズが大きくなると、必要な演算数も多くなり、推論にかかる時間も長くなる傾向にある。推論精度と推論速度はトレード・オフの関係にあるといえる。
モルフォでは、推論精度を下げることなく、またGPU等の特殊なプロセッサを利用しなくても、推論速度の高速化を可能とするソフトウェア「SoftNeuro®」を開発したので次章で紹介する。
深層学習推論高速化エンジン「SoftNeuro®」
1)SoftNeuro開発の背景
モルフォがSoftNeuroの開発を始めた背景には、深層学習に関連してご相談いただく内容が、変化してきたことがある(図2)。これまでは実験的な取り組みであったものが、実用化を目指したものに移行しつつある。
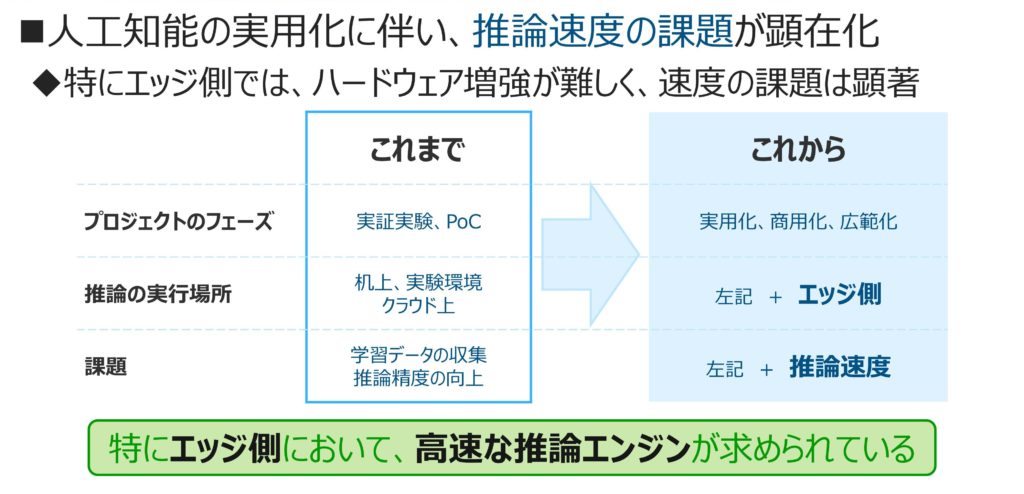
図2 SoftNeuro® 開発の背景
実験的な取り組みの際には、推論は社内に設置している、計算能力を潤沢に有するサーバ等で行っていたが、実用化となるとサーバ内とは限らず、比較的容積が小さく、計算能力も限られたエッジ側デバイス上で行う必要も出てくる。
また、そのデバイスが監視カメラや医療機器、ロボット等の場合、サイズ(容積)や発熱対策といった制約もある。そのため、GPUを搭載するといったハードウェア的な解決方法ばかりでなく、CPUを最大活用するソフトウェアによる解決策も求められるようになってきた。
2)SoftNeuroの特徴
上記のようなことを背景に、SoftNeuroは、特にエッジ側デバイスにおいて、CPUのみでも高速に深層学習の推論を行うことを目標にして開発された。
誤解なきよう補足すると、SoftNeuroは、深層学習の(学習のためのソフトウェアではなく)推論のためのソフトウェアである(図3)。

図3 SoftNeuro® は、推論ソフトウェア
SoftNeuroには、以下のような4つの特徴がある。
(A)世界最速級
SoftNeuroは、CPUのみの処理において世界最速級の処理速度を実現している。この高速性は、様々な手法(ニューラル・ネットワークの計算方法、メモリ使用方法等)を各プラットフォーム向けに最適化することで実現している。
図4、5は、他の推論エンジンとの処理速度を比較したグラフである。このグラフの縦軸には、インターネット上から入手可能な代表的な推論エンジンが並べられている。
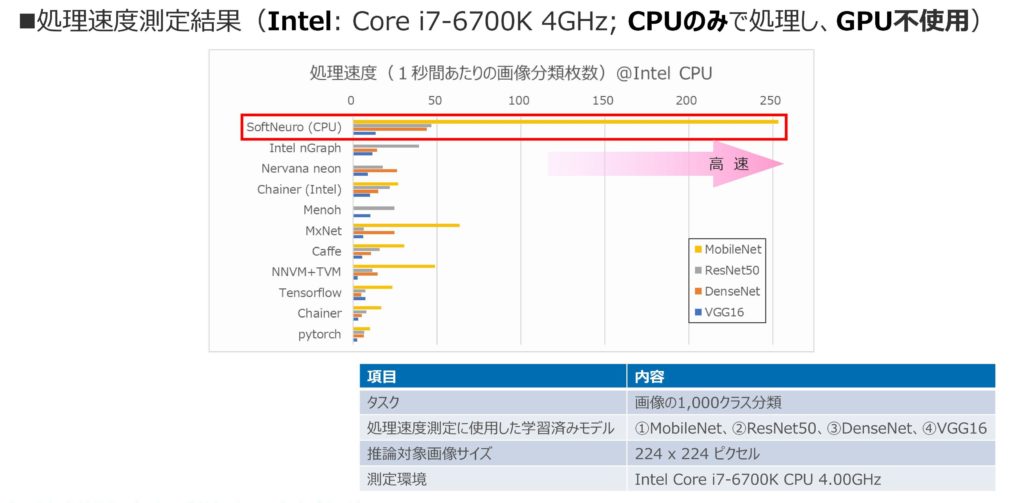
図4 SoftNeuro® の処理速度(Intel系CPU)
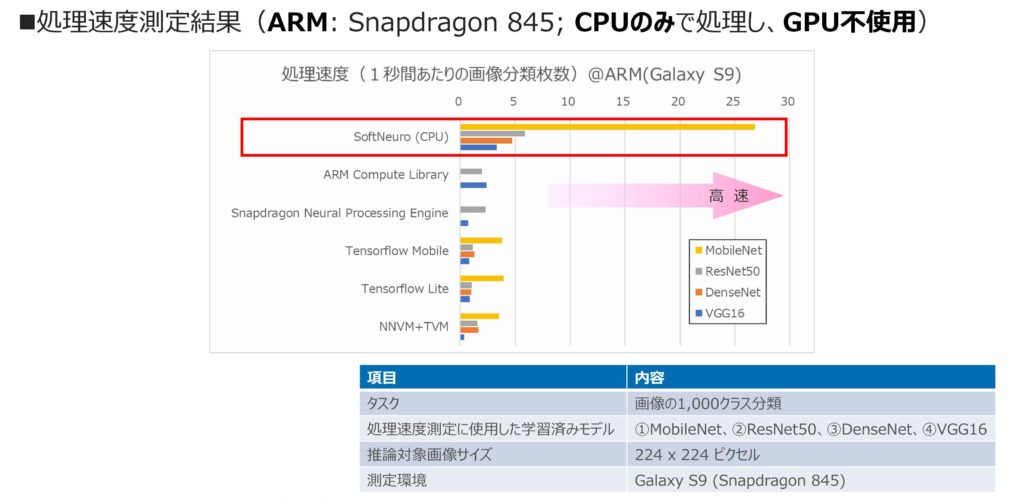
図5 SoftNeuro® の処理速度(ARM系CPU)
横軸は、処理速度を示しており、画像を1,000カテゴリに分類タスクを1秒間に何枚処理可能かをプロットしている。なお、測定の際、代表的なニューラル・ネットワーク・モデル4つ(VGG16, DenseNet, ResNet50, MobileNet)を使用している。
これらのグラフをご覧いただくと、CPUの種類(Intel系/ARM系)を問わず、高速に推論が可能であることがご理解いただけるだろう。
(B)マルチフレームワーク
深層学習の学習を行うフレームワークは、現在、Caffe、Kerasなど、オープンソースを中心に多数存在している。 SoftNeuroは、これらの主要なフレームワークの学習結果を活用可能である。
これまで利用してきたフレームワークの資産(学習結果等)を無駄にすることなく、推論処理部分の高速化や、マルチプラットフォーム対応を実現することが可能である。
なお、ソフトウェアで実装しているため、新しく登場するフレームワークおよびレイヤに順次対応可能となっている。
(C)マルチプラットフォーム
深層学習を用いて推論が行われる場所は、クラウド上のサーバに限らず、スマートフォンや自動車、産業機器等、多様化しつつある。
それらの実行環境では、CPUやOSといったプラットフォームが異なり、個別に移植や最適化といった作業が必要となっていた。
SoftNeuroは、現時点ではCPUのみで推論を実行可能であるが、順次多様なプラットフォームに応じた最適化(GPU、DSPの活用等)も行う予定である。
このマルチプラットフォーム対応により、学習結果を広範な動作プラットフォームへ展開することが容易になるだけでなく、動作プラットフォームの変更等に容易に対応可能となる。
(D)セキュアファイルフォーマット
深層学習を用いて推論が行われる場所が、スマートフォンや自動車、産業機器等、多様化していくということは、学習済みネットワークが様々な場所に複製されることであり、学習時のノウハウや結果(独自のネットワーク構造やウェイトパラメータ等)が漏洩するリスクが増大する。
SoftNeuroは、学習済みネットワークを暗号化する機能を標準で有するため、学習時のノウハウや結果の漏洩リスクの軽減を実現する。
さいごに
本稿では、まず深層学習の実用化が進んでいるという動向と、その際に顕在化することの多い課題を紹介した。
読者の中に、それらの課題に直面された方がいれば、課題解決のノウハウを有している企業に相談するとよいだろう。画像認識の分野においては、多数の商用化も含めた実績を有しているモルフォに相談していただきたい。
※ Intelは、アメリカ合衆国および/またはその他の国におけるIntel Corporationまたはその子会社の商標。
※ ARMは、米国およびその他の国におけるARM Ltd.の登録商標。
※Snapdragonは、Qualcomm Incorporatedの登録商標。
※SoftNeuroは、モルフォの登録商標。
■問い合わせ
株式会社モルフォ
イメージングAI事業部
TEL.03-3288-3230
E-mail:m-info-sales@morphoinc.com
http://www.morphoinc.com/






















コメントを残す