
急成長するIoT分野で重要なキーテクノロジーが、エッジコンピューティングとディープラーニングである。しかし、その融合にはまだまだ課題も多い。特に小型デバイス等にディープラーニングを組み込む開発環境は未整備である。
本稿では、エッジコンピューティングにおけるディープラーニングの有効性とともに、ディープラーニングを組込み分野に適用するための開発支援環境としてエンベデッドディープラーニングフレームワークKAIBER(カイバー)について概説する。
はじめに
20世紀前半からの絶え間ない情報通信革新の進展により、技術の価値が「計算機」から「ネットワーク」に、そして「データ」自体に移り変わっている。「ムーアの法則」「インターネット」「ビッグデータ」と10年単位で変遷するテクノロジーのキーワードの歴史は、今「人工知能」の時代に入ったと思われる。
ムーアの法則に象徴される1980年代、ミニコンやオフコン、そしてパソコンといった小型で安価なコンピュータが登場し、CPUの処理能力が毎年倍増していった。1990 年代、インターネットが登場し、2000年に入るころから、クラウドコンピューティンのコンセプトが注目されるようになった。その後、高速・広帯域のインターネットの技術進化とともに、クラウドコンピューティングは急速に普及した。
現在では、PCばかりでなく、スマートフォンやタブレット、ウェアラブル端末などが加わり、ソリューションの幅を広げている。インターネットにつながるデバイスは、家電製品や自動車、産業ロボットやビルの設備まで広がり、そこに組み込まれた多数のセンサが大量のデータを送り出すようになった。
そのために大量のデータがネットワーク帯域を圧迫する状況が生まれている。また、デバイスのデータをすべてクラウド側で処理する場合、ネットワークの遅延問題も大きな課題となっている。 産業ロボットを例にあげると、ネットワークに送り出しているデータの 90%以上は異常のないデータである。
これをすべてクラウドに保管し分析・処理する意味はきわめて小さく、システムのコストバランスも悪化する。また、瞬時にアラートを出し、次の制御に繋げたい場合は、ネットワーク遅延が発生するクラウド前提のシステムでは実現が難しい。このため、末端のデバイスもしくは、その周辺にエッジサーバと呼ばれる中間・分散処理の役割をもたせたシステムが普及の兆しを見せている。
IoTの普及とともに、クラウドだけでは実現できないネットワーク最適化や高速応答性を受け持つ役割として、エッジコンピューティングがますます注目されている(図1)。そして、そのコンセプトの重要なキーテクノロジーの1つがエンベデッドディープラーニングである。
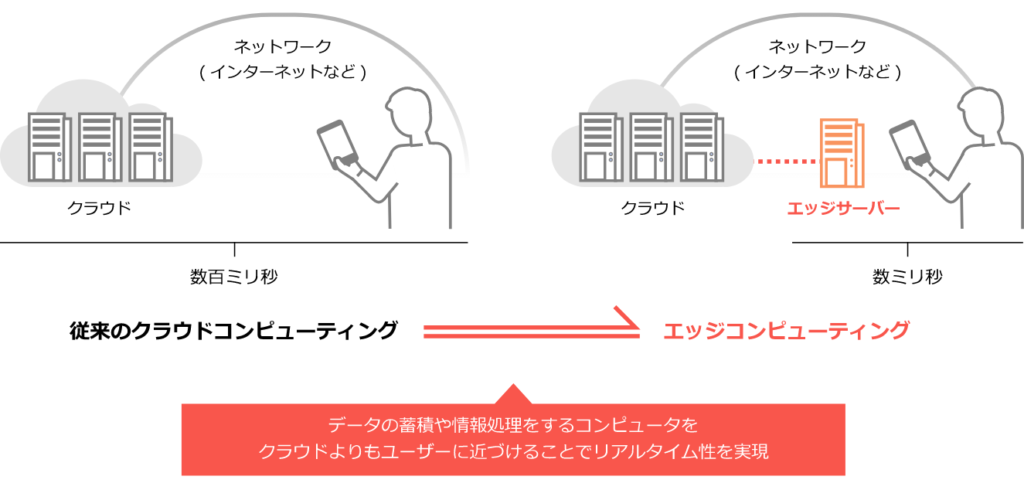
図1
クラウドの課題とエッジコンピューティング
ますます注目されるエッジコンピューティングであるが、基本は分散処理の考え方を発展させたものである。クラウドコンピューティングがもてはやされる以前も分散処理が大きなトレンドとなっていた。当時から比べればネットワーク帯域やサーバの処理能力も格段にアップし、その技術的背景からクラウドコンピューティングが生まれた。
そのトレンドが加速しIoTのコンセプトが広がり始め、繋がるクライアント(デバイス)数とデータ量は増大の一途である。IoTのコンセプトが浸透するほど、新たな課題もより顕著になる。IoTは大量のデータを集めて分析処理しフィードバックすることにより、より良いソリューションやサービスの提供に繋げていくことが目的である。
しかし、それをクラウドのみを前提にしたシステムで突き詰めようとすると、いろいろと問題が出てくる。上述したネットワーク帯域圧迫・リアルタイム性の欠如およびデータ保存の最適化という課題である。その解決策として注目されているのが、エッジコンピューティングとディープラーニングの組み合わせである。
組込みディープラーニング フレームワークの必要性
エッジコンピューティングは分散処理である」と解説した。ユーザと距離が近い環境で発生したデータを、リアルタイム性を保ちながら処理し、選択されたデータのみをクラウドに送って、ネットワーク帯域とクラウド上のデータ容量の膨張を抑えていく。
しかし、末端で発生する膨大なデータをクラウドより非力なエッジ側で処理しきれるのか、という問題に直面する。IoTは、多数のセンサやカメラから大量のデータが発生するのが前提であり、それを効率よく分析・処理できなければエッジコンピューティングは成り立たない(図2)。
そのためにはエッジ側の高度なインテリジェント化が必要である。デバイスの限られた処理能力を効率よく利用し、低消費電力でありながら、高度な分析・処理を行う技術である。その実現にはディープラーニングの導入が最適である。
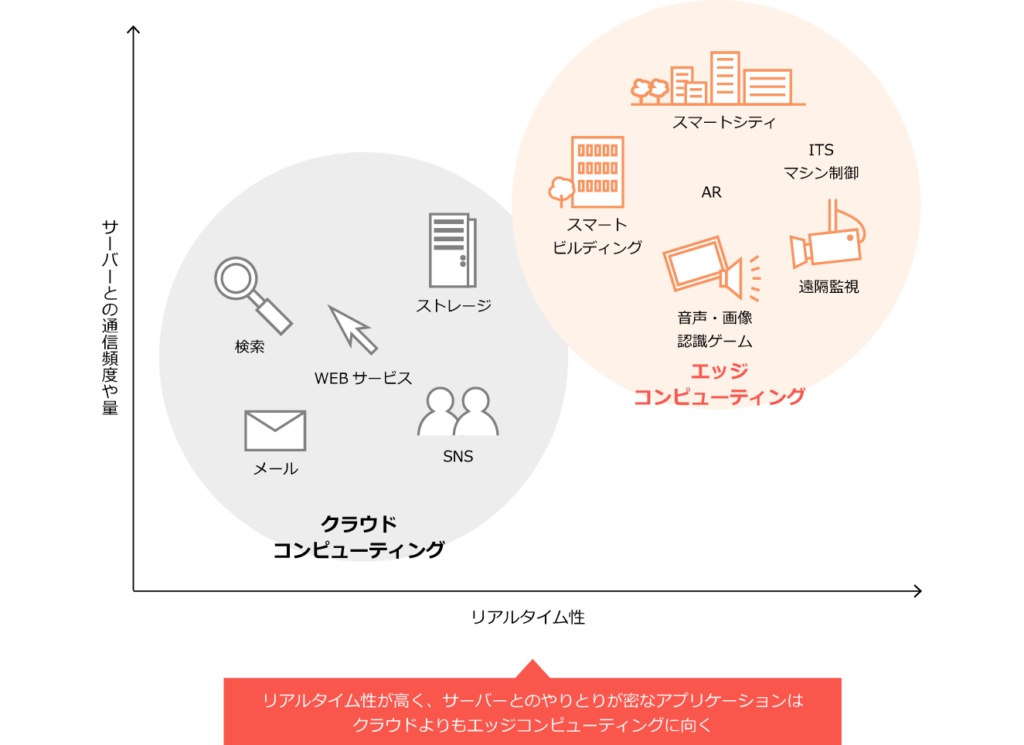
図2
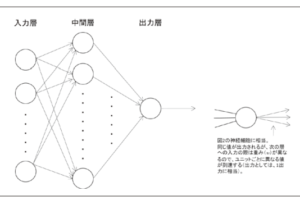
人工知能の代名詞となったディープラーニングであるが、一言で表すと「プログラムが大量データの特徴を精度よく自動で抽出・分析してくれる技術」である。現在のディープラーニングの導入事例が、ほとんどクラウド環境で構築されているのは、クラウドには大量のデータがあることとそれを処理する利用環境として強力なサーバが必要になるためである。
そのディープラーニングをエッジ側のデバイスに組み込んでインテリジェント化することが重要となりつつあるが、現状はその環境が十分整備されているとは言えない。 肝になるディープラーニングフレームワークのソリューションはいくつも存在するが、エッジ環境を考慮していないこととオープンソースが主流であることが主な理由である。
エッジ環境のセンサやカメラ等のデバイスに組み込めるようにディープラーニングフレームワークが設計されていないし、オープンソースであるため商用サポートが提供されておらず、開発・製品化を検討する企業側のハードルが高くなってしまっている。それを解決する手段として、弊社では国産初のエンベデッドディープラーニングフレームワーク「KAIBER」(カイバー)を開発した。次章にその概要を解説する。
「KAIBER」の詳細
KAIBERは、エッジコンピューティング向けに特化して開発したディープラーニングフレームワークとして次のような特徴がある。
➀ 国産初の小型デバイスへの組込みを前提に開発されたディープラーニングフレームワーク
現在、明確に組込み用途にフォーカスした汎用ディープラーニングフレームワークは皆無である。ラズベリーパイやスマートフォンでの利用を前提にした実装は一部に存在するが、エッジコンピューティングで利用される多種多用なマイコン環境まで想定していない。
➁ オープンソースでなく、商用サポートを提供
メジャーなフレームワークといえば、米国発のCaffeやTensorFlow、国産ではChainerなどがあるが、ほとんどがオープンソースである。ご存知のようにオープンソースは無償で公開されている反面、サポートサービスの保証がない。自社製品にディープラーニング技術を組込みたいが、開発中や出荷後の技術サポート体制でオープンソース採用を不安に感じる企業は多い。
➂ 組込みに適した推論実行環境と学習環境のモジュール化構造
デバイスに組み込む推論実行エンジンと大量のデータを学習するサーバ機能を完全に分離した設計になっている。推論実行エンジンはCライブラリとして提供され、組み込み技術者であれば容易に扱える。
➃ 業界最小クラスの省スペース・省リソース設計 組み込む推論実行エンジンは20数Kbyte程度のフットプリントであり、デバイスのROM容量を圧迫しない。組み込む際は同時に学習サーバ環境で生成された学習済みデータ(重みデータ)も必要になるが、ニューラルネットの設計によりデータ容量は増減するので、システム仕様に依存することになる。この学習済みデータ容量を抑えるノウハウが重要である。
➄ Non OS環境でも動作可能
推論実行エンジンは、シンプルなCライブラリであり、OS環境に依存しない。能であるし、OSがない環境にも移植可能である。
➅ 純国産によりマイコン・GPU・FPGA等の独自デバイスに最適化が容易
100%自社コードで開発しており、オープンソースのコードはベースにしていない。ディープラーニングの数値演算ライブラリも独自開発であり、コア部分から他者コードは排除している。このため、ユーザ固有の画像処理デバイスや今後、多数のチップベンダーからリリースされるAIチップにいち早く最適化できる構造と体制を実現している。組み込み分野では重要なポイントである(GPU対応としてCUDAライブラリは使用)。
➆ 標準GUIによる簡単操作
完全にGUIで統合したディープラーニング開発環境として設計されている。オープンソースのフレームワーク利用で難易度の高いディープニューラルネットの設計もGUIによる操作誘導機能と設定エラーの検知機構で、プログラム作法を覚える必要がない。
システム構成と組み込み手順
実際、ディープラーニング技術をターゲットデバイスに組み込む場合は、図3のシステム構成イメージとなり、手順は非常に簡単である。
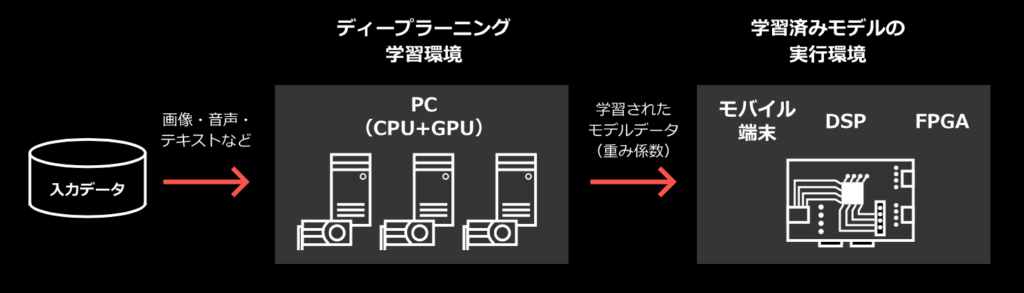
図3
まず、KAIBER学習機能はWindows環境GPU内臓のPCサーバで実行する。ディープラーニング学習終了後にエキスポートする学習済みファイルが1つ生成される。このファイルに重みデータやネットワーク構成を含むメタ情報がすべて入っており、推論実行エンジンのライブラリとともにターゲットデバイスに組み込むだけである。
推論実行エンジンはユーザの開発環境(コンパイラ)を利用した上で、Cライブラリとして納品されるが、ラズベリーパイ版とWindows DLL版の推論実行エンジンは標準でパッケージに入っているので、すぐに試すことも可能である。推論実行エンジンは、Cソース上では通常の関数として呼び出すだけであり、学習済みファイルをアップデートする仕組みを構築すれば、エッジ側でさらに賢いシステムに進化させられる。
因みに、ルネサスエレクトロニクス株式会社との協業により、ルネサス統合開発環境e2 studioとの連携機能を開発済みである。e2 studioでルネサス社提供のプラグイン「e-AI インポーター」を利用すると、KAIBERと連動して組み込み開発作業を容易に行えるようになっている。
実装事例
実際にデモ環境として構築した組み込みシステムの処理性能を紹介し、具体的なイメージを掴んでもらいたい。
• 図4:データテクノロジー(株)製評価ボード
• CPU:ルネサスエレクトロニクス RX63N 100MHz
• 監視カメラを接続し、MNIST手書き数字認識(CNN)を行う。
• DNN処理時間:50ms
• DNNの層:7
• RAM使用量:19KB(最大256KB)
• ROM使用量:384KB(最大2MB)

図4
ディープラーニングの世界でベンチマーク的に利用されるMNISTのデータセットを利用して実装したデモ環境である。ルネサス社の RX63N 100MHzを搭載しており、組み込み業界ではミッドローレンジのマイコンである。ディープニューラルネットの推論実行の処理時間は50ms程度と十分な速度を出し、RAMとROM容量も圧迫していない。
組み込む学習済みデータの増減は、ネットワークの層の深さや学習時の画像サイズに影響される。層が深く、画像サイズが大きければ推論精度も向上するが、計算量が増えるために推論スピードは遅くなる。精度を落とさず、ネットワークの層を少なくすることが設計上のノウハウとなる。
おわりに
ディープインサイトでは、エッジコンピューティングのコンセプトに基づき、組み込みディープラーニングが容易に実現できる開発環境の整備を目標に「KAIBER」を開発した。ユーザの既存製品にディープラーニングを組み込み、付加価値を向上させるツールとして今後も機能強化を図る計画である。下記HPを参照いただき、評価版による検証も検討いただきたい。
■問い合わせ先
ディープインサイト株式会社
TEL:03-6869-7564
E-mail:contact@deepinsight.co.jp
https://www.deepinsight.co.jp/



















コメントを残す